★引子
前天,俺在《俺的招聘经验[4]:通过笔试答题能看出啥?》一文,以“求质数”作为例子,介绍了一些考察应聘者的经验。由于本文没有政治敏感内容,顺便就转贴到俺在 CSDN 的镜像博客。
昨天,某个 CSDN 网友在留言中写道:
老实说,这个程序并不好写,除非你背过这段代码
如果只在纸上让别人写程序,很多人都会出错
但是如果给一台电脑,大多数人都会把这个程序调试正确
出这个题目没啥意义
只能让别人觉得你出题水平低
首先,这位网友看帖可能不太仔细。俺在文中已经专门强调过了,评判笔试答题,【思路和想法】远远比【对错】更重要,而他/她依然纠结于对错;其次,这位网友居然觉得这道题目没啥意义,这让俺情何以堪啊?!看来,有相当一部分网友完全没有领略到此中之奥妙啊!
算了,俺今天就豁出去了,给大伙儿抖一抖这道题目的包袱。当然,抖包袱的后果就是:从今天开始,就得把"求质数"这道题从俺公司的笔试题中去掉,然后换上另外一道全然不同的。这么好的一道题要拿掉,真是于心不忍啊 :-(
★题目
好,言归正传。下面俺就由浅入深,从各种角度来剖析这道题目的奥妙。
为了避免被人指责为“玩文字游戏”(有些同学自己审题不细,却抱怨出题的人玩文字游戏),在介绍各种境界之前,再明确一下题意。
前一个帖子已经介绍过,求质数可以有如下2种玩法。
◇需求1
请实现一个函数,对于给定的整型参数 N,该函数能够把自然数中,小于 N 的质数,从小到大打印出来。
比如,当 N = 10,则打印出
2 3 5 7
◇需求2
请实现一个函数,对于给定的整型参数 N,该函数能够从小到大,依次打印出自然数中最小的 N 个质数。
比如,当 N = 10,则打印出
2 3 5 7 11 13 17 19 23 29
★试除法
首先要介绍的,当然非“试除法”莫属啦。考虑到有些读者是菜鸟,稍微解释一下。
“试除”,顾名思义,就是不断地尝试能否整除。比如要判断自然数 x 是否质数,就不断尝试小于
x 且大于 1 的自然数,只要有一个能整除,则 x 是合数;否则,x 是质数。显然,试除法是最容易想到的思路。不客气地说,也是最平庸的思路。不过捏,这个最平庸的思路,居然也有好多种境界。大伙儿请看:
◇境界1
在试除法中,最最土的做法,就是:
假设要判断 x 是否为质数,就从
2 一直尝试到 x-1。这种做法,其效率应该是最差的。如果这道题目有10分,按照这种方式做出的代码,即便正确无误,俺也只给1分。◇境界2
稍微聪明一点点的程序猿,会想:x 如果有(除了自身以外的)质因数,那肯定会小于等于
x/2,所以捏,他们就从 2 一直尝试到 x/2 即可。这一下子就少了一半的工作量哦,但依然是很笨的办法。打分的话,即便代码正确也只有2分。
◇境界3
再稍微聪明一点的程序猿,会想了:除了
2 以外,所有可能的质因数都是奇数。所以,他们就先尝试 2,然后再尝试从 3 开始一直到 x/2 的所有奇数。这一下子,工作量又少了一半哦。但是,俺不得不说,依然很土。就算代码完全正确也只能得3分。
◇境界4
比前三种程序猿更聪明的,就会发现:其实只要从
2 一直尝试到 √x,就可以了。估计有些网友想不通了,为什么只要到 √x 即可?简单解释一下:
因数都是【成对】出现滴。比如,100的因数有:1和100,2和50,4和25,5和20,10和10。看出来没有?成对的因数,其中一个必然小于等于100的开平方,另一个大于等于100的开平方。至于严密的数学证明,用小学数学知识就可以搞定,俺就不啰嗦了。
◇境界5
那么,如果先尝试
2,然后再针对 3 到 √x 的所有【奇数】进行试除,是不是就足够优了捏?答案显然是否定的嘛?写到这里,才刚开始热身哦。一些更加聪明的程序猿,会发现一个问题:尝试从
3 到 √x 的所有【奇数】,还是有些浪费。比如:要判断
101 是否质数,101 的根号取整后是 10,那么,按照境界4,需要尝试的奇数分别是:3,5,7,9。但是你发现没有,对 9 的尝试是多余的。不能被 3 整除,必然不能被 9 整除......顺着这个思路走下去,这些程序猿就会发现:其实,只要尝试小于 √x 的【质数】即可。而这些质数,恰好前面已经算出来了(是不是觉得很妙?)。所以,处于这种境界的程序猿,会把已经算出的质数,先保存起来,然后用于后续的试除,效率就大大提高了。
顺便说一下,这就是算法理论中经常提到的:【以空间换时间】。
◇补充说明
开头的4种境界,基本上是依次递进的。不过捏,境界5跟境界4,是【平级】滴。在俺考察过的应聘者中,有人想到了境界4但没有想到境界5;反之,也有人想到境界5但没想到境界4。通常,这两种境界只要能想到其中之一,俺会给5-7分;如果两种都想到了,俺会给8-10分。
对于俺要招的“初级软件工程师”的岗位,能同时想到境界4和境界5,应该就可以了。如果你对自己要求不高,仅仅满足于浅尝辄止。那么,看到这儿,你就可以打住了,无需再看后续的内容;反之,如果你比较好奇或者希望再多学点东西,请接着往下看...
★筛法
◇何为“筛法”?
说完“试除法”,再来说说筛法(维基百科的解释在“这里”)。俺不妨揣测一下:本文的程序员读者,应该有2/3以上,从来没有听说过筛法。所以捏,顺便跟大伙儿扯扯蛋,聊一下筛法的渊源。
这个筛法啊,真的是一个既巧妙又快速的求质数方法。其发明人是公元前250年左右的一位古希腊大牛——埃拉托斯特尼。为啥说他是大牛捏?因为他本人精通多个学科和领域,至少包括:数学、天文学、地理学(地理学这个词汇,就是他创立的)、历史学、文学(他是一个诗人)。真的堪称“跨领域的大牛”。
他最让俺佩服的是:仅仅用简单的几何方法,测量出了地球的周长、地球与月亮的距离、地球与太阳的距离、赤道与黄道的夹角......而且,这些计算结果跟当代科学家测出的,相差无几。要知道他生活的年代,大概相当于中国的春秋战国。而咱们的老祖宗,一直到明朝还顽固地坚信:天是圆的、地是方的、月亮会被天狗给吃喽......
好了,扯蛋完毕,言归正传。
估计很多人把筛法仅仅看成是一种具体的方法。其实,【筛法还是一种很普适的思想】。在处理很多复杂问题的时候,都可以看到筛法的影子。那么,筛法如何求质数捏,说起来很简单:
首先,2是公认最小的质数,所以,先把所有2的倍数去掉;然后剩下的那些大于2的数里面,最小的是3,所以3也是质数;然后把所有3的倍数都去掉,剩下的那些大于3的数里面,最小的是5,所以5也是质数......
上述过程不断重复,就可以把某个范围内的合数全都除去(就像被筛子筛掉一样),剩下的就是质数了。俺在维基百科上找了一张很形象的动画,能直观地体现出筛法的工作过程。
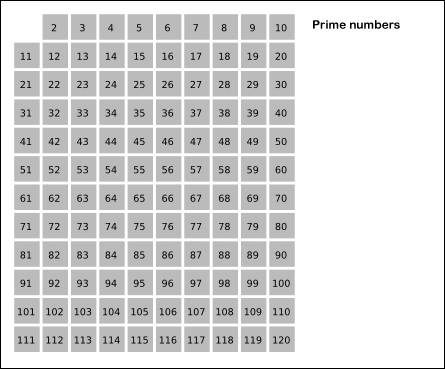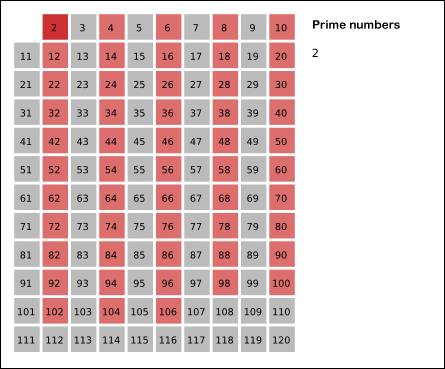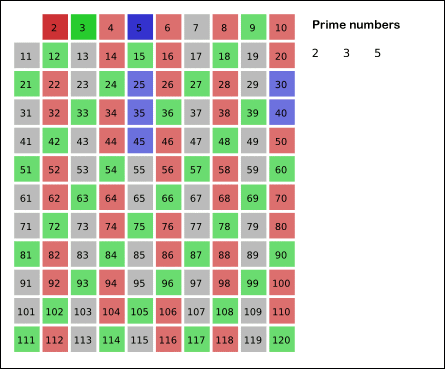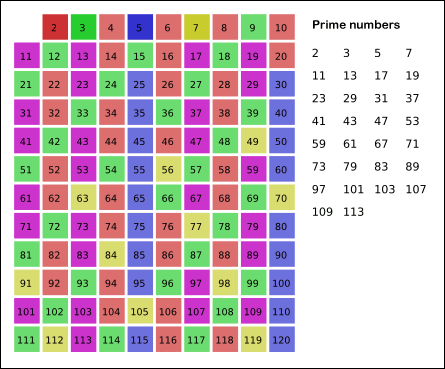
明白了“筛法”的原理,大伙儿应该看出,筛法在速度上是明显优于“试除法”的。当然,筛法的程序实现也分为不同的境界。而且,筛法可讲究的门道更多了。下面,俺分别从不同角度,聊一聊筛法都有哪些讲究。
◇如何确定质数的分布范围?
这是采用筛法首先会碰到的问题。文本开头给出的那两种需求,其处理的方式完全不同,俺分别说一下。
需求1
对于需求1,这个自然不是问题。因为在需求1中,质数的分布范围就是 N,已经给出了,很好办。
需求2
但是对于需求2,就难办了。因为需求2给出的 N,表示需要打印的质数的个数,那么这 N 个质数会分布在多大的范围捏?这可是个头疼的问题啊。
但是,来应聘的程序猿如果足够牛的话,当然不会被这个问题难倒。因为素数的分布,是有规律可循滴——这就是大名鼎鼎的素数定理。
稍微懂点数学的,应该知道素数的分布是越往后越稀疏。或者说,素数的密度是越来越低。而素数定理,说白了就是数学家找到了一些公式,用来估计某个范围内的素数,大概有几个。在这些公式中,最简洁的就是
x/ln(x),公式中的 ln 表示自然对数(估计很多同学已经忘了啥叫自然对数)。假设要估计1,000,000以内有多少质数,用该公式算出是72,382个,而实际有78,498个,误差约8个百分点。该公式的特点是:估算的范围越大,偏差率越小。有了素数定理,就可以根据要打印的质数个数,反推出这些质数分布在多大的范围内。因为这个质数分布公式有一定的误差(通常小于15%)。为了保险起见,把反推出的素数分布范围再稍微扩大15%,应该就足够了。
可能有同学会质疑俺:谁有这么好的记性,能够在笔试过程中背出这些质数分布公式捏?
俺觉得:背不出来是正常滴。但是,对于有一定数学功底的应聘者,假如他/她知道质数分布公式,即便不能完整写出来,只要在答题中体现出:“此处通过质数分布公式推算范围”,那么俺也是认可滴。
再啰嗦一次:关键是看 idea!
◇如何设计存储容器?
知道了分布范围,接下来就得构造一个容器,来存储该范围内的所有自然数;然后在筛的过程中,把合数筛掉。那么,这个容器该如何设计捏?不同层次的程序猿,自然设计出来的容器也不同啦。
境界1
照例先说说最土的搞法——直接构造一个整型的容器。在筛的过程中把发现的合数删除掉,最后容器中就只剩下质数了。
为啥说这种搞法最土捏?
首先,整型的容器,浪费内存空间。比方说,你用的是32位的 C/C++ 或者是 Java,那么每个 int 都至少用掉【4个字节】的内存。当 N 很大时,内存开销就成问题了。
其次,当 N 很大时,频繁地对一个大的容器进行删除操作可能会导致频繁的内存分配和释放(具体取决于容器的实现方式);而频繁的内存分配/释放,会导致明显的 CPU 占用并可能造成内存碎片。
境界2
为了避免境界1导致的弊端,更聪明的程序猿会构造一个定长的布尔型容器(通常用数组)。比方说,质数的分布范围是1,000,000,那么就构造一个包含1,000,000个布尔值的数组。然后把所有元素都初始化为 true。在筛的过程中,一旦发现某个自然数是合数,就以该自然数为下标,把对应的布尔值改为 false。
全部筛完之后,遍历数组,找到那些值为 true 的元素,把他们的下标打印出来即可。
此种境界的好处在于:其一,由于容器是定长的,运算过程中避免了频繁的内存分配/释放;其二,在某些语言中,布尔型占用的空间比整型要小。比如 C++ 的 bool 仅用1字节
注:C++ 标准(ISO/IEC 14882)【没有】硬性规定
sizeof(bool) == 1,但大多数编译器都实现为单字节。境界3
虽然境界2解决了境界1的弊端,但还是有很大的优化空间。有些程序猿会想出按位(bit)存储的思路。这其实是在境界2的基础上,优化了空间性能。俺觉得:C/C++ 出身的或者是玩过汇编语言的,比较容易往这方面想。
以 C++ 为例。一个 bool 占用1字节内存。而1个字节有8个比特,每个比特可以表示0或1。所以,当你使用按位存储的方式,一个字节可以拿来当8个布尔型使用。所以,达到此境界的程序猿,会构造一个定长的 byte 数组,数组的每个 byte 存储8个布尔值。空间性能相比境界2,提高8倍(对于 C++ 而言)。如果某种语言使用4字节表示布尔型,那么境界3比境界2,空间利用率提高32倍。
★总结
看到俺写“总结”二字,很多网友心想:总算看完了,知道该怎么求质数才是最优的了。
其实,你们又错了,本文才写了不到一半。考虑到篇幅已经有点长,而且俺打了这么多字,也有点累了,暂时刹住话匣子,下次接着聊。
希望看了今天这个介绍,大伙儿应该明白一个道理:山外有山、天外有天。每一个技术领域里面的每一个细小的分支,深究下去都有很多的门道与奥妙。在你深究的过程中,必然会学到很多东西。深究的过程也就是你能力提高的过程。
本文后续的内容,会介绍刚才提到的按位存储法还有哪些缺陷,该如何解决。另外,还会介绍其它一些求质数的方法。
版权声明
本博客所有的原创文章,作者皆保留版权。转载必须包含本声明,保持本文完整,并以超链接形式注明作者编程随想和本文原始地址:
https://program-think.blogspot.com/2011/12/prime-algorithm-1.html
本博客所有的原创文章,作者皆保留版权。转载必须包含本声明,保持本文完整,并以超链接形式注明作者编程随想和本文原始地址:
https://program-think.blogspot.com/2011/12/prime-algorithm-1.html








74 条评论
2012电影里,美国总统对那年轻的科学家说;一个科学家胜过100个政治家。
回复删除这题如果在考试的时候没有给出N的大小,筛法并不能说比普通方法优越,不过是空间换时间和时间换空间,题目中又没有说看重速度。如果是我答这个题很可能在知道筛法的情况下依然选用普通方法,因为我不知道有多大内存。
回复删除你依然可以使用筛法计算出一定范围内的质数,如果不够,再用试除法去解决剩余的质数。
删除筛法并不优越:
回复删除1. 除法变乘法而已,效率并没提高(次数并没减少),相反,增加了运算,比如6,试除时,除以2即被否决(一次除法),筛法中,会被2、3的倍数重复地过滤(两次乘法)。
2. 空间浪费,不现实。
在正确的筛法中,6 并不会被重复过滤两次。
删除请仔细看动画,或者看看俺在 5楼3单元 的留言
如果我没记错的话,C++的bool应该是4bytes
回复删除显然是你记错了,1 byte,自己看
删除http://msdn.microsoft.com/en-us/library/tf4dy80a.aspx
to 2楼的同学:
回复删除恰恰是因为 N 是不确定的,才更加能看出一个程序猿的水平。
另外,能够想到筛法的同学,即便用试除法,通常也能够同时做到境界4和境界5。这样的人通常是有机会进入面试阶段的。
而在面试阶段,俺就会拿这个题目试探应聘者。俺会问:在不同的硬件环境中,当N较大时,该如何处理?
to 3楼的同学:
当你认为6会被重复过滤两次时,就已经暴露出你并没有深刻领会筛法的奥妙。请仔细看动画。
to 4楼的同学:
你应该记错了。
大部分C++编译器都把 sizeof(bool)实现为1,虽然C++标准没有显式规定。
我觉得前四楼是一个人
删除关于3楼的问题和博主的答复
删除动画中6没有被染绿色应该是动画本身的bug,12不是由红变绿了吗?
对于筛法来说,重复过滤往往难以避免。
TO 2单元的同学
删除看来你真的没理解筛法的奥妙之一。
当筛除 3 的倍数时,直接从 9 开始。
当筛除 5 的倍数时,直接从 25 开始。
为啥是这样?请自己思考一下。
@3單元
删除思考了五分鐘,成功得出答案,果然是奧妙之一。
文章里的简单筛法确实会重复过滤,比如30。当然有其它线性的筛法。另外,啥时候出下篇呀
删除TO 编程随想
删除又看了看图,明白了。
7x7以下是7x6=6x7=3x14、7x5=5x7……,已经在前面被计算过了!
博主的思维果然非同凡想啊
对于程序员来说,掌握试除法和基本筛法就够了。
回复删除验证质数,可参考wiki上的质数条目,写得比较全,不过对数学功底的要求较高。
对于一些特定形式的质数,有快速验证算法的,还有分布式计算项目是算特定形式的质数的,如梅森素数,PrimeGrid等。
本人参加PrimeGrid,找到过几个大质数,曾经是TOP 5000质数里的,可是被后来算出更大质数的挤出5000以外了 :(
。。这搞得跟考OI一样了啊。。
回复删除第一反应Miller-Rabin...
回复删除个人觉得这题对于搞ACM的人来说实在是小菜一碟了 = =
回复删除筛数法是数论最基本的题目之一,相比斐波那契数列的N多变种简单多了。。。就更不要说涉及图论,高精度,搜索,动规,以及各种坑爹的树了。。。囧
当然,LZ很好的利用了这条经典题目~
数据结构与算法分析,什么时候都是基础中的基础啊
都说大公司笔试考的就是算法,果然不假。可惜,周围大部分的人对算法并不重视。一心就想着搞可视化编程,做UI。。。
0. 整型对吧,有符号,32位,最大2147483647,最快的方式--查表。但这也是最耗内存的,但这取决于实际情况。
回复删除1. 没有那么多资源,要尽量快?首先,你可能需要一个好的算法,这样的算法网上定能找到相应的参考,但是大多数人都不能手写出来,你可以手写出来么?所以,你说的算法上的境界,只是自娱自乐而已,你给台联网的电脑,你出这个题目试一试?
2. 如果你说,求素数实在是瓶颈了,你又不能拿出那么多内存来,好的方法可能还是查表,不过要按照现实中出现N的范围分段查,这样平均复杂度也会低很多,如果N超出了范围,你再用找到的最好的算法去多出来的那一段。一般来说应该存那些较大的素数。
3.如果觉得直接存指数到表里面浪费内存,那你可以用bit来代表一位数,比如,1Byte可以表示8位以内的素数,2Bit可以表示16位以内的素数,你还是觉得耗内存,好吧,内存太紧张了,又想最快,又不知道用在什么环境下,能把2~N分段计算么?支持多线程么?
4.产生N这个源的分布是什么?如果就计算一次(或者几次)N,而且不知道大小,也不准有look up table. 只能现算,好吧!你出了一个ACM问题。如果要平凡的计算这样的N,是不是可以考虑cache?
5. 幸好你说明了N是整型,不用考虑大整数,否则又是一个问题了。
我想说的是,这种面试题只是简单的给出了问题,你没有构造出一个确切的需求,然后期待面试者按照你意淫出来的境界一层一层的给你惊喜,你后面又说,只要面试者的idea体现出来了就行,不用给出正确解。大家都是受了好多年应试教育的,你读书答证明题的时候随便写"此处通过质数分布公式推算范围",老师会给你分么?你有这么勇敢过么?你在题目中交代,“只要写出思路也行”的提示么?
我觉得,你真不如把这个题目分成如下两个问答题:
0. 请问你知道求素数有那些最快的方法?(可自己分情况给出答案)
1. 假如现在有大量的整型数需要缓存,有什么好的方法减少内存占用?
我觉得面试也是被面试,没必要搞得那么装逼。
楼主给点评一下:
回复删除实现打印:
http://blog.csdn.net/program_think/article/details/7032600#reply
哈哈,N种境界还,好好学学数论不吧,费马小定理都不知道就不要在这扯淡了
回复删除to 楼上的网友
回复删除介绍N种境界,自然要由浅入深,方可体现出条理性。如果一上来就张口闭口“数论”,岂不是要吓到一片?
本文才刚讲到“筛法”的开头,不要着急。
再说了,数论并非考察软件开发人员的重点。俺不想反客为主。
to 前2楼的网友
请问哪个回复需要俺点评?
to 前3楼的网友
感谢写了这么长的回复。
俺出的笔试题,确实没有明确给出一些限制条件(比如:性能的要求、对环境的要求)。
俺是这样考虑的:
如果某个应聘者在没有强调性能的情况下,依然写出性能尽量好的代码,这足以说明此人的能力和习惯。
反之,如果某个应聘者能力很强,本来可以写出筛法,但是因为题目没要求,导致此人仅仅写出试除法。这也没有太大关系。
因为一个能力强的人,即使用试除法,也能同时考虑境界4和境界5。这样的话,多半是能够通过笔试这关。到了面试的时候,俺就会针对性地提一些问题,其能力自然就能见分晓。
0.如果A用了试除法达到境界5,并写出了代码,B就写了“筛法”; 那你觉得A强还是B强?你更需要哪个?
回复删除1.如果C和D用同一种算法,并实现了代码,D用C语言实现的,无递归;C用Lisp实现的,用了尾递归;D的速度肯定比C的快,但C的代码比D的短好几倍;你觉得哪个更强?
如果单单从算法角度,达到境界4和5根本不算强,这和知识面有关,有些人知道筛法,有些人知道Miller-Rabin,有些人知道Sieve of Atkin,但是知道不代表其整体能力就强,不代表实现出来的代码就漂亮,这里面有多处权衡,很难因为算法上的一些trick而评出境界。
我觉得,有时候面试者看重的是一个人的审美观,这些东西大多数时候只能从代码里面看出来。比如怎样尽量减少内存跳跃访问,怎样减少不必要的IO,怎样命名函数和变量,怎样写注释,怎样设计接口,怎样避免undefined行为,对内存模型的理解和运用等。
当然,如果要上机,这个操作上有难度了。
但有一点我持不同意见的:这里的境界的评定是有失偏颇的,一个有经验的不知道筛法的程序员看看wiki就能立马实现出一个漂亮的算法出来,但是看到你的考卷的时候他可能真的只能写出试除法,并且没有达到境界5.
此评论已被作者删除。
回复删除#include
回复删除using namespace std;
#define N 10000
int main()
{
bool bNum[N];
int i,k;
for(i=0;i<N;i++) bNum[i]=true;
for(i=0;i<N;i++)
{
if(bNum[i])
{
for(k=2;((i+2)*k)<N+2;k++)
bNum[(i+2)*k-2]=false;
}
}
for(i=0;i<N;i++)
{
if(bNum[i])
{
cout<<"The prime numbers less than N are: "<<i+2<<endl;
}
else continue;
}
return 0;
}
你说的素数定理是不是说用
回复删除#define MAX N*log(N)*1.15就可以表示最大范围呢?
在ch ina ,一个政治家胜于千千万万名科学家
回复删除此评论已被作者删除。
回复删除to 阿成:
回复删除在不考虑偏差的情况下,相当于解如下的方程
x / ln(x) = N
解出来的 x 就是你要用的最大范围 MAX
考虑上偏差的话,再对 MAX 乘以 1.15
to 前三楼的评论者:
回复删除俺在前面的帖子《通过笔试答疑能看出啥?》有介绍过:笔试阶段是为了淘汰掉80%的人。因此,俺不是根据笔试答题来判断谁更合适。笔试题目只是为了淘汰掉某些人。
当然,再完美的笔试题目,也有可能发生少数的误判,导致好的人反而被淘汰掉。
以这道题目为例,确实可能有某个优秀的应聘者用了C语言写了试除法,但是却连境界4和境界5都没有考虑到。并因此没能进入面试阶段。
但是俺个人觉得:这样的概率应该挺小的。
优秀的开发人员,应该比较容易想到(境界4和境界5)的其中之一。
再来说说你举的4个例子。
说实在的,俺碰到的面试者,平均素质都不是很高。(很有可能是因为俺公司不是知名的牛B公司,优秀的人看不上)
大部分人都只是用常见的语言(比如C/C++/Java)实现了试除法的前3种境界之一。
在这种情况下,如果某个应聘者能用 Lisp 答出此题;或者某个应聘者能够体现出筛法的idea;或者某个应聘者能够写出试除法的后两种境界之一。
那么,俺通常都会让他们进入面试阶段。
至于你提到的命名、注释等代码层面的问题,俺同样很看重。
关于这点,俺在《通过笔试答疑能看出啥?》一文已经说了。
在不考虑偏差的情况下,相当于解如下的方程
回复删除x / ln(x) = N
解出来的 x 就是你要用的最大范围 MAX
考虑上偏差的话,再对 MAX 乘以 1.15
-------------------------------------------
这是超越方程,好像不太好解呀。
wiki上面说素数定理可以给出第n个素数p(n)的渐近估计:
p(n)~n*ln(n)
不知道是怎么来的。而且不知道这个系数是多少。
把x=n*ln(n)代到方程里面去就成了
n*ln(n)/ln(n*ln(x))=n,好像是说ln(ln(x))可以忽略?
弱爆了,没有任何新意的思想或观点,完全给那些没有专门学过算法的编程初学者看的。这种涉及初等算法的题目作为计算机等级考试来考本科生还可以,怎么能作为面试题呢?对于一个学过离散数学和解析数论的数理专业学生来说,直接达到最高境界是很自然的事情。算法均来源于数学理论,而数学家是在研究数学,程序员只是在应用数学,因此搞程序的人玩数学永远玩不过数学家。
回复删除to 楼上的同学:
回复删除听你的口气,貌似数学功底不错嘛。
但是,千万不要以为这道题仅仅是考“算法”或者是考“数学”。
这道题考察的知识面可广呢!
你提到说:
“对于一个学过离散数学和解析数论的数理专业学生来说,直接达到最高境界是很自然的事情。”
俺要提醒一下:
本文仅仅是一个开头,离最高境界还早着呢 :)
有兴趣的话,可以看俺后续的内容。
再提醒一下:
不论是哪个学术领域,都是山外有山、天外有天。不可轻言“最高境界”。
在此我也要指出几点:
回复删除1.文章中提出的素性检验都是确定性算法,即对于一个自然数是否素数给出确定的结论。目前效率最高的是2002年一个印度计算机教授M.Agrawal和他的两个本科生宣布的,对于整数n只要使用O((logn)^12)次位运算。在假定素数密度猜想成立的条件下,还可以改进到只要O((logn)^6)次位运算。
2.除确定性算法外还有概率素性检验法,这种方法能知道一个自然数是否有很高的可能性是素数,但不确定到底是否素数。这种算法在素性检验有关的程序中是有很重要的应用的!
3.为了要找出前N个素数,你在这里提到的是通过素数定理来估算需要在多大的范围内进行筛选。事实上还有另一种思路,为了要找出前N个素数,就需要知道第N个素数有多大。素数定理的推论给出了估算第N个素数大小的近似表达式:令Pn是第n个素数,其中n是正整数,那么Pn~nlogn
注:素数密度猜想:p是素数,那么2p+1也是素数
另注:在所有的数论书中都是用log表示自然对数而不是ln,这与其它地方不同
我可以用LISP语言实现,不过你说的存储容器的问题,我对Java这种语言不熟,所以不太清楚这个概念
当然,既然你说这只是个开头,离最高境界还早着了,我倒是期待你会出一篇更高层次的文章
to gengyu89
回复删除你这次的留言显然比前一次要有价值,表扬一下 :)
关于“AKS素数判定法”
你所说的“效率最高的算法”,应该就是指“AKS素数判定法”吧?
据说2002年的那个版本,已经不是最牛的啦。
2005年,另2个牛人搞出了该算法的变体,运算次数降为O((logn)^6),且不再依赖于Sophie Germain质数的分布(也就是你说的素数密度猜想)
俺顺手把论文链接找来了:
http://www.math.dartmouth.edu/~carlp/aks041411.pdf
http://www.math.dartmouth.edu/~carlp/PDF/complexity12.pdf
顺便补充一下,AKS的牛逼之处在于它是第一个同时满足如下4条的素数判定法:
1、通用性
2、多项式时间
3、确定性的
4、不依赖未证明的猜想
关于“确定性检验”和“概率检验”
如果严格按照题意,显然不能用概率检验法。
不过话说回来,假如某个应聘者能用概率检验法解答此题(虽然不能算完全答对),但这样的应聘者,能力会胜过仅仅用试除法且完全答对的人。
这也就是俺在《通过笔试答题能看出啥》一文中着重强调的:"思路和想法"远远比"对错"更重要。
关于“ln”和“log”的写法
首先声明,俺不是数学专业出身,至今也没有看过一本正规的数论教材。估计大部分程序员也没看过。而 Windows 的计算器,大部分程序员是用过滴。它上面用 ln 表示自然对数。
所以,ln 这个写法,对程序员读者来说,应该比较容易理解。
去年看这个帖子,没有弄懂,现在才勉强看懂一些,原来一个看似简单的算法,包含着这么多层境界。
回复删除初学Python,我第一次想到的也是试除法,其他的暂时都没想明白。
牛人就是多,一辈子也达不到这个高度了。。。
回复删除C++初学者路过。。。我竟然直接想到了试除法境界5!(正在做project euler problem3)
回复删除我只是想说,一个看过答案和没看过答案的能力相差多少?
回复删除关于是否看过答案,可分为4类:
删除1、原本就会,没看过答案
2、原本就会,看过答案
3、原本不会,没看过答案
4、原本不会,看过答案
只有第4类人是有争议的。
任何一种面试题,其实都难以做到完美。
出题的人也需要与时俱进,不断想出新的花样,尽量减低第4类人的比例。
这道面试题似乎是在挑选ACM人才。公司的程序员在实际编程中,碰到这种问题的可能性几乎为零。而且工作经验越久,平时不用的数学知识忘得越多。
回复删除确实有很多数学知识会遗忘,所以俺才挑选了小学数学的“质数和整除”,这个是不太可能忘掉的。
删除另外,这道题考察了非常基本的算法思想——[b]用空间换时间[/b]
虽然实际工作中不太可能碰到“求质数”,但是,实际工作中碰到的很多性能优化问题,都是用的“[b]用空间换时间[/b]”的思想。
我猜想素数分布式越来越稀,那么素数的总个数范围有限,根据干法,存储一个既有的素数表得了,判断是不是素数可以直接按表查找。
回复删除拜托,公元前300年的欧几里德已经证明素数无穷
删除需求是有限的,这里又不是搞数学研究,我上面的话不严谨。而且计算机本是就是有限的,只要达成既定目的就行
回复删除基础差露馅就不要狡辩了。
删除再抓个逻辑问题,人家讨论求质数的算法,这就是既定目的。你却要先来个质数表。
我之前的回复确实没有把限定条件说明白。素数无穷小学生都知道,小学数学里有一节是介绍的用计算机求得迄今为止的最大素数,也不时有计算最大质素的新闻。我把我之前话再重复一遍“素数分布式越来越稀,那么某一范围内的素数的总个数范围有限,根据干法,存储一个既有的素数表得了,判断是不是素数可以直接按表查找,大素数可以单独讨论”。
删除不知道你是怎么判断我基础差的,你记得欧几里得干过什么就能证明基础不差了?“我猜想”三个字完全是出于对这篇没有写完的文章的敬意,没有动手比较过各种算法的保留。我也拜托,匿名有意思么
再者,这么干我不是第一个,《c++编程艺术》里面有说这个的,无可厚非。质素表确实可以用来加快求质素的过程,随便google了一下真有这么干的。
类似于与先把结果先算出来的把戏,其实应用还是蛮多的。提高效率,首先要提高完成单个目标的效率,然后减少完成多个目标之间的重复,还要将任务适当的排序,或者并发。后者不是复杂度什么的吗
回复删除提高原子操作的效率是一方面,但是有蚂蚁算法这样的另类,就不能说一味的提高原子操作的效率就可以了。处理复杂性,就应该充分利用计算机的性能,比如有限元求解,针对复杂边界条件,只要把问题网格化就能得到近似的结果。我猜想这个质素题目的最高境界里面一定有一个阶段是面对一个超巨量的需求,将需求化整为零,各个击破,用不着什么这原理那原理。 我曾经求过一个圆形散粒体(多尺度)在限定的边界内随机分布的问题,要求圆不相交,且要求出分布的最大密度。这是我理解的处理复杂的艺术
回复删除博主你的后续还没出来啊.. 等着看精彩的呢
回复删除近期忙着写政治、心理学、网络安全。
删除看了一下本文的发布日期,没想到已经过去一年了!
也不知道啥时候能抽空把本文的后续写完 :(
囧
删除山外有山、天外有天。每一个技术领域里面的每一个细小的分支,深究下去都有很多的门道与奥妙。在你深究的过程中,必然会学到很多东西。深究的过程也就是你能力提高的过程。
回复删除记下了
怎么都没人说cpu算乘法比除法快?
回复删除这才是第二种方法真正的优势吧
俺觉得:
删除CPU 对乘法和除法的性能差异,可以忽略不计。
两者的主要差异在于,“筛法”的运算总次数更少(尤其是相对于“试除法”的前3种境界)。
看看Intel的优化手册就知道32位/64位的整数乘法和整数除法之间的差异是很大的。
删除TO 2单元的网友
删除多谢发表不同观点 :)
看问题要抓“主要矛盾”。
乘法和除法之间的性能差异不是主要矛盾。
主要矛盾是“筛法”的运算总次数远远小于“试除法”(尤其是相对于“试除法”的前3种境界)。
换句话说:
乘法相对于除法导致的性能提升,应该占小头;而运算总次数的显著下降才是性能提升的大头。
在软件编程层面越过编译器差异论底层在现实中遇到的可能性不高吧?初级的不会有那么深入的了解;高级的这样的问题有些太大了,不如直截了当问了
删除呵呵 张益唐已经证明了质数不是越到后来越稀疏
回复删除这是个重大突破
仔细看了楼主的思路,怎么找不到后续的了?有后续境界吗?
回复删除4/5用vector push_back 和预先定义差不了多少
回复删除inline int si(int n){
int L= 1.5*n/log(double(n));
return floor(double(L)) ;
}
int countPrimes2(long n){
if (n <2 ) return 0;
if (n == 2) return 1;
if (n<=2) return 0;
int M=si(n);
M = (M>1000)?M:200;
int * iL = new int[M];
int s;
int i;
int L = 1;
iL[0]=2;
for (i =3; i<=n; i++){
s=0;
for (int j =0; (j < L) & (iL[j]*iL[j] <= n) ;j++){
if (i%iL[j]==0)s++;
}
if (s==0) { iL[L]=i;L++;}
}
delete[] iL;
return L;
}
思路1/2其实尾递归形式上很漂亮,但是低效:
long countPrimes(long n, long a){
long isp = 1;
if (n%2 == 0) {
isp=0;
}else{
for (long i=1;i<(n/2)-1;i++) {
if ( n%(2*i+1) == 0) {
isp=0;
break;
}
}
}
return (n==2)?a:countPrimes(n-1,a+isp);
}
long countPrimes(long n) {
if (n <2 ) return 0;
if (n == 2) return 1;
return countPrimes(n,1);
}
不用筛法很难达到O(n loglog n)....
啥时候出下一篇呐?
回复删除不錯不錯,學習了。我還不知道我的小伙伴們只不知掉篩法呢……嘿嘿。
回复删除小学时就看过埃拉托斯特尼素数筛,然而到现在仍然不怎么懂编程。
回复删除其实并不需要求范围。比如先求1000以内的质数,不够再求1000-2000的质数,并和前面的合并,质数也可以结合前面的结果来筛选。如此可以一直迭代下去,也不用一下分配很大的内存。
回复删除再次找到太监。
回复删除又又又又又又找到太监了。
回复删除此评论已被作者删除。
回复删除2018年的知乎live
回复删除求质数表的n种境界
https://www.zhihu.com/lives/951407164133216256
https://www.zhihu.com/lives/951407442270138368
这些思想如果不是大牛研究出来,您可以自己研究出来吗?
回复删除知识无价,寻求最优解是好的。
回复删除gkd,更新啊随想老兄
回复删除从这篇文章可以看出阮博主很擅长数学,不晓得党国为啥非要让他死在狱中不可。法国数学家安德烈·韦伊在狱中提出如何利用有限域上的黎曼猜想,被称为韦伊猜想,这一发现直接启发了后来的数学大师格罗滕迪克,并最终由皮埃尔·德利涅证明,这让他获得了菲尔兹奖。
回复删除如果党国那么着急把他弄死在狱中,那就完全抹杀了这种可能性了。阿基米德临死前让杀他的罗马士兵不要弄乱他画的圆圈,士兵勃然大怒,拔剑杀死阿基米德。共产党的水平就和这个无知的罗马士兵差不多,要把阮晓寰弄死。
有传言一号发话,曝光家族信息的今年一律清理,阮晓寰恐怕活不到出狱
删除