关于并发的场景,在之前的帖子“进程还线程?是一个问题!”中,已经专门论述了进程和线程各自的优缺点,两者皆不可偏废。所以,后面对各种缓冲区类型的介绍都会同时提及进程方式和线程方式。
★线程方式
先来说一下并发线程中使用队列的例子,以及相关的优缺点。
◇内存分配的性能
在线程方式下,生产者和消费者各自是一个线程。生产者把数据写入队列头(以下简称 push),消费者从队列尾部读出数据(以下简称 pop)。当队列为空,消费者就稍息(稍事休息);当队列满(达到最大长度),生产者就稍息。整个流程并不复杂。
那么,上述过程会有什么问题捏?一个主要的问题是关于内存分配的性能开销。对于常见的队列实现:在每次 push 时,可能涉及到【堆内存】的分配;在每次 pop 时,可能涉及【堆内存】的释放。假如生产者和消费者都很勤快,频繁地 push、pop,那内存分配的开销就很可观啦!对于内存分配的开销,用 Java 的同学可以参见前几天的帖子“Java 性能优化[1]”;对于用 C/C++ 的同学,想必对 OS 底层机制会更清楚,应该知道分配【堆内存】(new 或 malloc)会有加锁的开销和用户态/核心态切换的开销。
那该怎么办捏?请听下文分解,关于“生产者/消费者模式[3]:环形缓冲区”。
◇同步和互斥的性能
另外,由于两个线程共用一个队列,自然就会涉及到线程间诸如同步啊、互斥啊、死锁啊等等劳心费神的事情。好在"操作系统"这门课程对此有详细介绍,学过的同学应该还有点印象吧?对于没学过这门课的同学,也不必难过,网上相关的介绍挺多的(比如“这里”),大伙自己去瞅一瞅。关于这方面的细节,咱今天就不多啰嗦了。
这会儿要细谈的是,同步和互斥的性能开销。在很多场合中,诸如信号量、互斥量等玩意儿的使用也是有不小的开销的(某些情况下,也可能导致用户态/核心态切换)。如果像刚才所说,生产者和消费者都很勤快,那这些开销也不容小觑啊。
这又该咋办捏?请听下文的下文分解,关于“生产者/消费者模式[4]:双缓冲区”。
◇适用于队列的场合
刚才尽批判了队列的缺点,难道队列方式就一无是处?非也。由于队列是很常见的数据结构,大部分编程语言都内置了队列的支持(具体介绍见“这里”),有些语言甚至提供了线程安全的队列(比如JDK 1.5引入的 ArrayBlockingQueue)。因此,开发人员可以捡现成,避免了重新发明轮子。
所以,假如你的数据流量不是很大,采用队列缓冲区的好处还是很明显的:逻辑清晰、代码简单、维护方便。比较符合 KISS 原则。
★进程方式
说完了线程的方式,再来介绍基于进程的并发。
跨进程的生产者/消费者模式,非常依赖于具体的进程间通讯(IPC)方式。而IPC的种类名目繁多,不便于挨个列举(毕竟口水有限)。因此咱们挑选几种跨平台、且编程语言支持较多的IPC方式来说事儿。
◇匿名管道
感觉管道是最像队列的IPC类型。生产者进程在管道的写端放入数据;消费者进程在管道的读端取出数据。整个的效果和线程中使用队列非常类似,区别在于使用管道就无需操心线程安全、内存分配等琐事(操作系统暗中都帮你搞定了)。
管道又分“命名管道”和“匿名管道”两种,今天主要聊匿名管道。因为命名管道在不同的操作系统下差异较大(比如 Win32 和 POSIX,在命名管道的 API 接口和功能实现上都有较大差异;有些平台不支持命名管道,比如 Windows CE)。除了操作系统的问题,对于有些编程语言(比如 Java)来说,命名管道是无法使用的。所以俺一般不推荐使用这玩意儿。
其实匿名管道在不同平台上的 API 接口,也是有差异的(比如 Win32 的 CreatePipe 和 POSIX 的 pipe,用法就很不一样)。但是我们可以仅使用标准输入和标准输出(以下简称 stdio)来进行数据的流入流出。然后利用 shell 的管道符把生产者进程和消费者进程关联起来(没听说过这种手法的同学,可以看“这里”)。实际上,很多操作系统(尤其是 POSIX 风格的)自带的命令都充分利用了这个特性来实现数据的传输(比如 more、grep 等)。
这么干有如下几个好处:
1. 基本上所有操作系统都支持在 shell 方式下使用管道符。因此很容易实现跨平台。
2. 大部分编程语言都能够操作 stdio,因此跨编程语言也就容易实现。
3. 刚才已经提到,管道方式省却了线程安全方面的琐事。有利于降低开发、调试成本。
当然,这种方式也有自身的缺点:
1. 生产者进程和消费者进程必须得在同一台主机上,无法跨机器通讯。这个缺点比较明显。
2. 在一对一的情况下,这种方式挺合用。但如果要扩展到一对多或者多对一,那就有点棘手了。所以这种方式的扩展性要打个折扣。假如今后要考虑类似的扩展,这个缺点就比较明显。
3. 由于管道是 shell 创建的,对于两边的进程不可见(程序看到的只是 stdio)。在某些情况下,导致程序不便于对管道进行操纵(比如调整管道缓冲区尺寸)。这个缺点不太明显。
4. 最后,这种方式只能单向传数据。好在大多数情况下,消费者进程不需要传数据给生产者进程。万一你确实需要信息反馈(从消费者到生产者),那就费劲了。可能得考虑换种 IPC 方式。
顺便补充几个注意事项,大伙儿留意一下:
1. 对 stdio 进行读写操作是以阻塞方式进行。比如管道中没有数据,消费者进程的读操作就会一直停在哪儿,直到管道中重新有数据。
2. 由于 stdio 内部带有自己的缓冲区(这缓冲区和管道缓冲区是两码事),有时会导致一些不太爽的现象(比如生产者进程输出了数据,但消费者进程没有立即读到)。具体的细节,大伙儿可以看"这篇文章"。
◇SOCKET(TCP 方式)
基于 TCP 方式的 SOCKET 通讯是又一个类似于队列的 IPC 方式。它同样保证了数据的顺序到达;同样有缓冲的机制。而且这玩意儿也是跨平台和跨语言的,和刚才介绍的 shell 管道符方式类似。
SOCKET 相比 shell 管道符的方式,有啥优点捏?请看:
1. SOCKET 方式可以跨机器(便于实现分布式)。这是主要优点。
2. SOCKET 方式便于将来扩展成为多对一或者一对多。这也是主要优点。
3. SOCKET 可以设置阻塞和非阻塞方法,用起来比较灵活。这是次要优点。
4. SOCKET 支持双向通讯,有利于消费者反馈信息。
当然有利就有弊。相对于上述 shell 管道的方式,使用 SOCKET 在编程上会更复杂一些。好在前人已经做了大量的工作,搞出很多 SOCKET 通讯库和框架给大伙儿用(比如 C++ 的 ACE 库、Python 的 Twisted)。借助于这些第三方的库和框架,SOCKET 方式用起来还是比较爽的。由于具体的网络通讯库该怎么用不是本系列的重点,此处就不细说了。
虽然 TCP 在很多方面比 UDP 可靠,但鉴于跨机器通讯先天的不可预料性(比如网线可能被某个傻X给拔错了,网络的忙闲波动可能很大),在程序设计上我们还是要多留一手。具体该如何做捏?可以在生产者进程和消费者进程内部各自再引入基于线程的“生产者/消费者模式”。这话听着像绕口令,为了便于理解,画张图给大伙儿瞅一瞅。
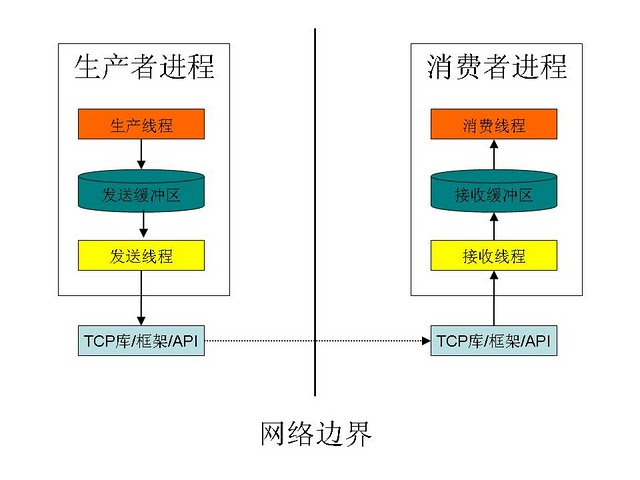
这么做的关键点在于把代码分为两部分:生产线程和消费线程属于和业务逻辑相关的代码(但和通讯逻辑无关);发送线程和接收线程属于通讯相关的代码(但和业务逻辑无关)。
这样的好处是很明显的,具体如下:
1. 能够应对暂时性的网络故障。并且在网络故障解除后,能够继续工作。
2. 网络故障的应对处理方式(比如断开后的尝试重连),只影响发送和接收线程,不会影响生产线程和消费线程(业务逻辑部分)。
3. 具体的 SOCKET 方式(阻塞和非阻塞)只影响发送和接收线程,不影响生产线程和消费线程(业务逻辑部分)。
4. 不依赖 TCP 自身的发送缓冲区和接收缓冲区。(默认的 TCP 缓冲区的大小可能无法满足实际要求)
5. 业务逻辑的变化(比如业务需求变更)不影响发送线程和接收线程。
针对上述的最后一条,再多啰嗦几句。如果整个业务系统中有多个进程是采用上述的模式,那或许可以重构一把:在业务逻辑代码和通讯逻辑代码之间切一刀,把业务逻辑无关的部分封装成一个通讯中间件(说“中间件”显得比较牛逼 :-)。如果大伙儿对这玩意儿有兴趣,以后专门开个帖子聊。
下一个帖子,咱们来介绍一下环形缓冲区的话题。
回到本系列的目录
版权声明
本博客所有的原创文章,作者皆保留版权。转载必须包含本声明,保持本文完整,并以超链接形式注明作者编程随想和本文原始地址:
https://program-think.blogspot.com/2009/03/producer-consumer-pattern-2-queue.html
本博客所有的原创文章,作者皆保留版权。转载必须包含本声明,保持本文完整,并以超链接形式注明作者编程随想和本文原始地址:
https://program-think.blogspot.com/2009/03/producer-consumer-pattern-2-queue.html








10 条评论
这个系列的文章太好了,受益良多,多谢多谢,期待下文。
回复删除"如果整个业务系统中有多个进程是采用上述的模式,那或许可以重构一把:在业务逻辑代码和通讯逻辑代码之间切一刀,把业务逻辑无关的部分封装成一个通讯中间件"
回复删除能否指点一二?
楼上的同学,
回复删除因为发送和接收线程不依赖于具体业务逻辑,可以考虑抽象成一个通用的东东(用于通讯功能)。
楼主您好,最后一段说的,在业务逻辑代码和通讯逻辑代码之间切一刀,把业务逻辑无关的部分封装成一个通讯中间件,是不是就是对应你后面介绍的ZMQ?也就是说ZMQ就是一个封装好的网络通讯库?那它的名称为啥有MQ呢?它和消息队列有什么关系呢?
删除谢谢博主深入浅出的讲解.
回复删除另外还有个问题:抽象出来的通讯中间件是不是只能和业务组件进行进程间通信,无法实现上面那张图的架构?
楼上的同学,
回复删除我原文中的意思是:把通讯相关的部分(发送和接收线程)抽象为一个通用的、进程内的模块。以后其它程序需要进行类似的SOCKET通讯,直接调用该模块即可。
该通讯模块和业务模块之间,是进程内通讯,不是进程间通讯。
写的很好。以前有些模棱两可的概念想不明白,看了你这个系列清楚多了。
回复删除非常好的文章,看了后真的学到很多的东西~~~谢谢楼主~~
回复删除请问博主,要更详细地了解IPC,缓冲区的知识,什么书比较好。
回复删除真清晰,网上这样的精品博文真少,内容排版都很赞
回复删除